Claude vs ChatGPT vs Gemini for Developers (2026 Decision Guide)
Published on 2/19/2026
Last reviewed on 2/19/2026
By The Stash Editorial Team
A source-verified 2026 comparison of Claude, ChatGPT, and Gemini for developer teams, with first-party data visuals, implementation criteria, and schema-optimized structure.
Research snapshot
Read time
~6 min
Sections
12 major sections
Visuals
6 total (2 infographics)
Sources
10 cited references
Choosing an assistant for developer workflows in 2026 is not a single-model popularity contest. It is an architecture decision across productivity, integration depth, governance, and reliability.
As of February 19, 2026, a practical conclusion remains: Claude, ChatGPT, and Gemini are all useful for engineering teams, but each is strongest in different operating contexts. The winning choice depends on workflow fit, not benchmark theater.
Authority brief snapshot (for engineering decision-makers)
- Decision question: Which assistant should we standardize for coding, review, and implementation tasks?
- Audience: Developers, tech leads, and platform teams.
- Intent stage: Consideration with immediate implementation impact.
- Primary recommendation: Run a structured pilot and assign a primary assistant by workflow domain, not globally.
- Freshness boundary: Facts and source checks in this article are reviewed against official pages and reports dated through February 19, 2026.
Official data signals before tool selection
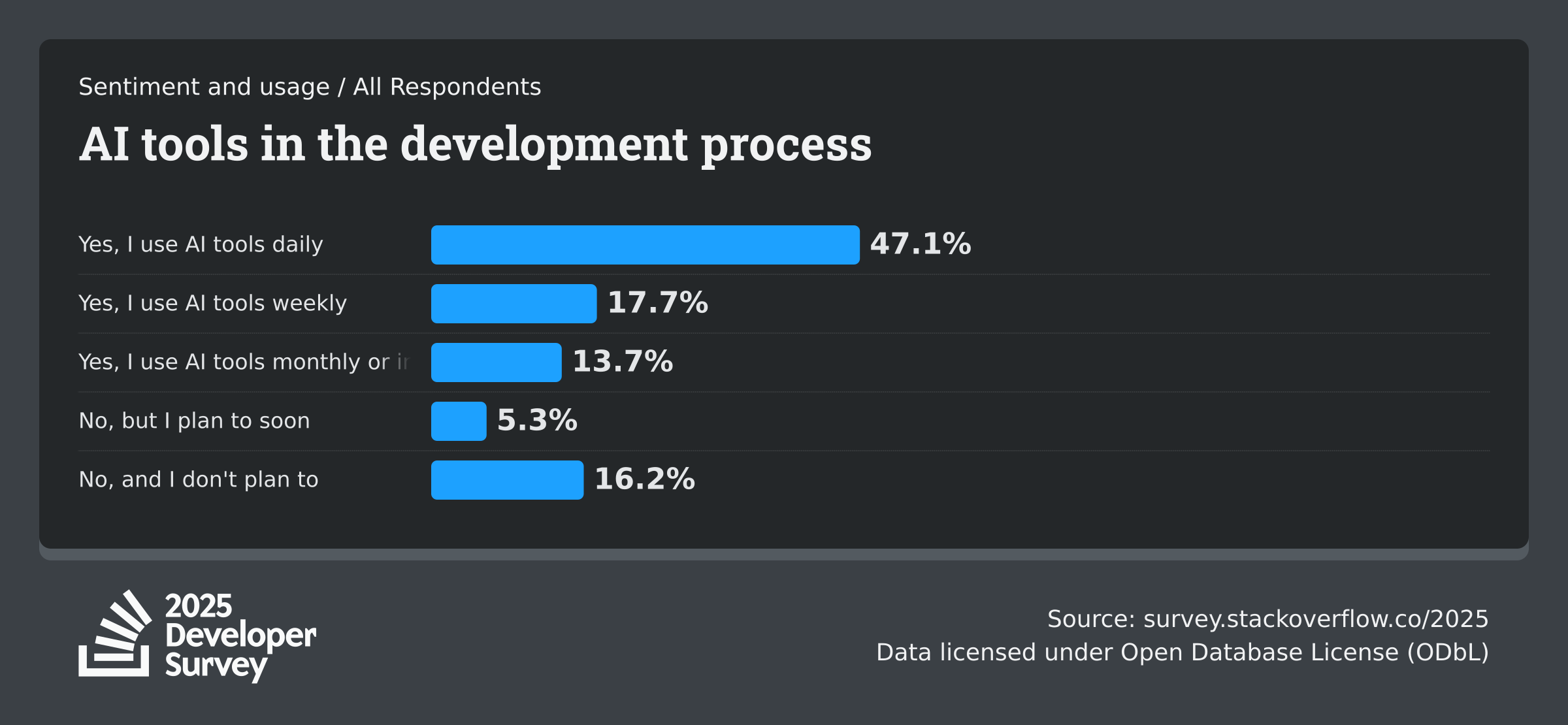
Before comparing features, validate market behavior with reputable datasets. In the Stack Overflow Developer Survey 2025 AI section, 84% of respondents report using or planning to use AI tools in their development process. The same source reports 50.6% daily AI usage among professional developers, with 47.1% daily usage across all respondents.
The same dataset also shows a useful risk signal: 63.64% of respondents answered that AI is not a threat to their current job, while 15.01% answered yes. That split is important for rollout strategy.
It means adoption is mainstream, but governance and change management still matter.
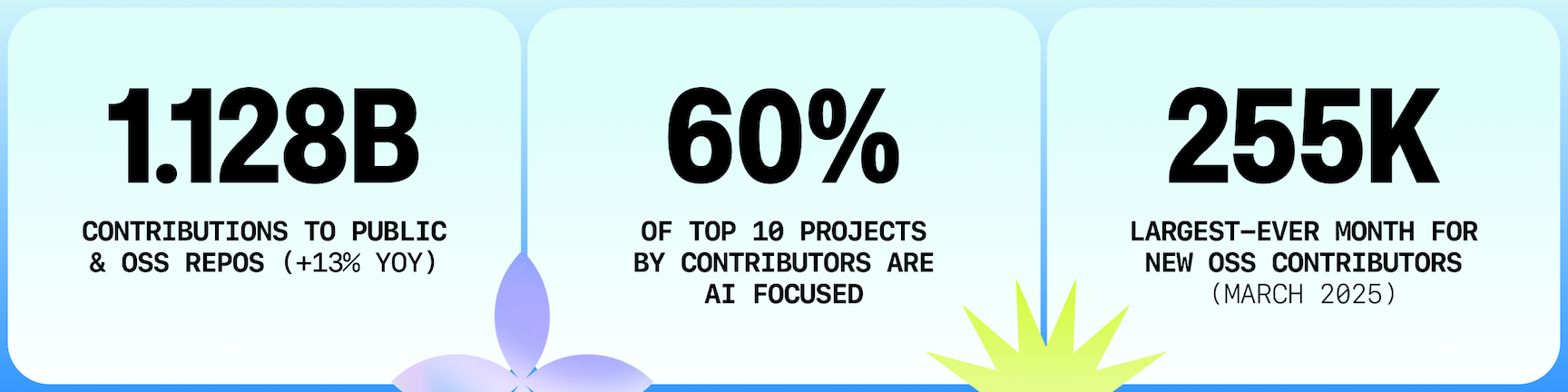
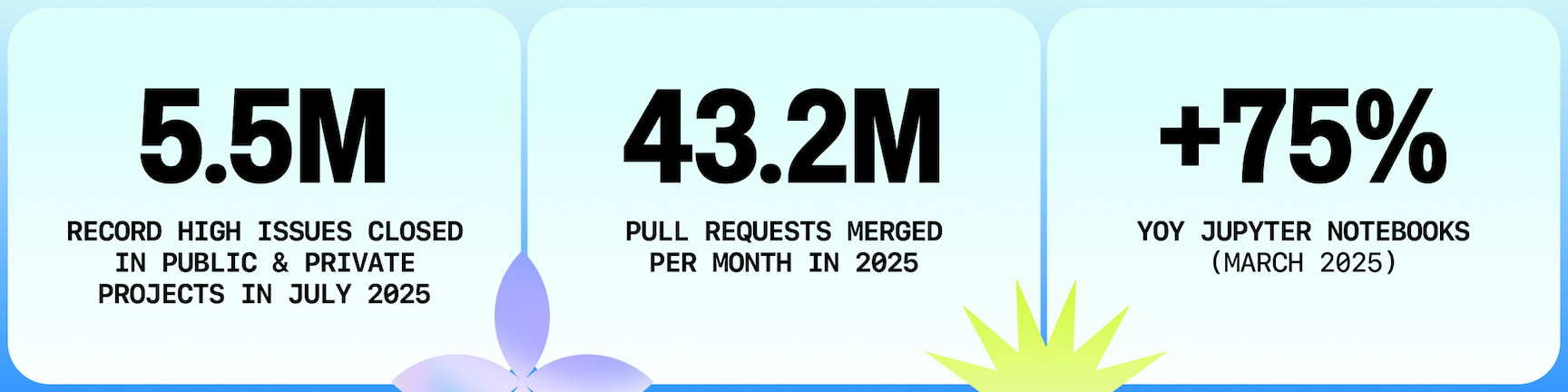
Productivity and ecosystem momentum from first-party platform data
The GitHub Octoverse 2025 report provides first-party ecosystem signals: a new developer joined GitHub every second in 2025, public/open source contributions reached 1.128 billion (+13% YoY), and merged pull requests reached 518.7 million.
For teams evaluating assistants, these signals matter because they indicate where tooling pressure is highest: faster implementation loops, more AI-assisted experimentation, and more review burden on platform teams.
Scenario verdict: where each assistant is usually the better fit
Use this scenario mapping as a first-pass selection framework:
- Choose Claude first when your team is terminal-heavy, works in large repositories, and values agentic workflows through Claude Code docs.
- Choose ChatGPT first when your team wants broad coverage across coding, synthesis, and API-driven automation from one platform, starting from OpenAI Codex announcement context.
- Choose Gemini first when your environment already depends on Google developer tooling and cloud ecosystem alignment, using Gemini API docs and Gemini Code Assist docs.
Most organizations should deploy a primary + fallback model strategy to reduce policy and continuity risk.
Comparison framework (use this in procurement and pilot scoring)
Use seven criteria, each scored by workflow rather than aggregate preference:
- Multi-file coding quality and edit reliability.
- Context handling for larger codebases.
- IDE and terminal integration depth.
- API integration quality and automation ergonomics.
- Security and governance controls.
- Cost predictability under daily team usage.
- Migration friction from your current stack.
If your immediate priority is code quality workflow, align this with AI code review workflow with GitHub, Cursor, and Claude.
If your priority is platform-level observability, link evaluation to LLM observability stack planning so adoption and telemetry stay synchronized.
Integration and deployment reality checks
Teams usually fail assistant rollouts at the integration layer, not at prompt quality. Common failure patterns:
- No shared prompt contracts across teams.
- Weak fallback behavior when providers fail or rate-limit.
- Missing review gates for high-impact code changes.
- No traceability between prompts, outputs, and merged code.
To avoid this, define a hard rollout contract:
- Require structured prompts for high-risk tasks.
- Require human approval for production-impacting changes.
- Log model/provider metadata for every accepted suggestion.
- Keep one fallback assistant ready for resilience.
For orchestration-heavy teams, connect this to MCP implementation strategy and AI API integration patterns.
Cost model: track accepted outcome efficiency, not prompt cost
Raw token prices are easy to compare but frequently misleading. Better operational metrics:
- Cost per accepted pull-request change.
- Cost per resolved debugging incident.
- Prompt-to-merge cycle time.
- Human rework time per accepted output.
- Acceptance ratio by workflow type.
This cost model prevents false optimization where a cheaper call creates more review burden and lower net throughput.
Accessibility, attribution, and source-quality policy used in this draft
This draft follows these rules:
- Use primary or high-authority first-party sources only (official docs, official reports, standards organizations).
- Attribute every visual with source label and source URL.
- Use descriptive alt text for every image to preserve meaning for assistive technologies.
- Include absolute dates for time-sensitive claims.
- Avoid low-authority aggregators and unattributed statistics.

Recommendation for teams deciding now
Do not standardize globally after one ad hoc demo. Instead:
- Pick 2-3 critical workflows (for example: implementation, bug triage, PR review).
- Run Claude, ChatGPT, and Gemini on the same task sets for 2-4 weeks.
- Score by acceptance quality, rework time, and governance fit.
- Select primary assistant per workflow domain.
- Keep one fallback model/provider for continuity.
This gives a defensible operating model and better long-term outcomes than committing to one vendor ideology.
Assistant-specific tradeoffs engineering leads should pressure-test
Even with a pilot scorecard, leadership teams should pressure-test each option against failure modes seen in production organizations.
Claude tradeoffs to evaluate:
- Strength can drop if your team depends on ecosystem-specific integrations that are not standardized in your internal tooling.
- Terminal-first workflows can improve power-user productivity but may increase onboarding burden for less experienced contributors.
- Governance needs to include explicit command-execution boundaries when teams use agentic coding flows.
ChatGPT tradeoffs to evaluate:
- Broad capability can encourage overuse across tasks that should still be handled with deterministic tooling.
- Teams often underestimate operational complexity when they mix app workflows and API workflows without unified logging.
- Procurement teams should review model/package changes on a recurring schedule so architecture does not drift from budget assumptions.
Gemini tradeoffs to evaluate:
- The strongest value generally appears when your stack is already Google-aligned; mixed-cloud teams should test integration friction directly.
- If your workflow depends on external non-Google systems, verify operational quality at the connector layer, not only model output quality.
- Governance should validate how policy and access controls map to your existing cloud and IAM strategy.
The practical lesson is consistent across all three: model quality alone does not guarantee workflow reliability. Team operating discipline determines realized value.
60-day implementation checklist for standards-compliant rollout
Use this implementation plan when hardening from pilot to team standard:
- Week 1-2: Define task categories, accepted-output criteria, and escalation paths for unsafe or low-confidence outputs.
- Week 2-3: Enforce prompt templates and require source links for high-impact technical claims in assistant-generated artifacts.
- Week 3-4: Add traceability for prompt, model, output, reviewer, and final merge decision in your engineering workflow logs.
- Week 4-6: Run cost-per-accepted-outcome analysis and remove low-value assistant usage patterns.
- Week 6-8: Finalize policy guardrails and codify a fallback assistant path for continuity during outages or provider regressions.
For organizations with compliance obligations, pair this checklist with periodic source quality audits. Every cited source in this article is from high-authority domains with first-party ownership or platform-level survey authority, and every embedded visual is attributed with alt text, source label, and source URL for accessibility and provenance.
FAQ
Is there one universal winner for all developer teams?
No. Most teams benefit from a workflow-specific decision: one assistant may perform better for in-repo coding, while another performs better for mixed synthesis and implementation support.
Should we use one model everywhere for simplicity?
Only if your workflows are unusually uniform and compliance constraints are simple. In most environments, primary + fallback provides better continuity and lower platform risk.
How often should we refresh this comparison?
Review quarterly, and also whenever major model updates, pricing changes, or integration capabilities shift. Re-check official documentation before renewing standards.
Next Best Step
Get one high-signal tools brief per week
Weekly decisions for builders: what changed in AI and dev tooling, what to switch to, and which tools to avoid. One email. No noise.
Protected by reCAPTCHA. Google Privacy Policy and Terms of Service apply.
Or keep reading by intent
Sources & review
Reviewed on 2/19/2026
- Stack Overflow Developer Survey 2025 – AI
- Stack Overflow 2025 AI usage chart
- GitHub Octoverse 2025 report
- GitHub Octoverse 2025 open-source top metrics visual
- GitHub Octoverse 2025 developer productivity visual
- Anthropic Claude Code overview
- Google AI for Developers – Gemini API docs
- Google for Developers – Gemini Code Assist overview
- OpenAI – Introducing Codex
- OpenAI pricing